Pre-Proposal: Decentralized Metrics & SLA Foundations for NaaP
Executive Summary
The Cloud Special Purpose Entity (Cloud SPE) proposes a focused effort to improve the reliability, transparency, and usability of the Livepeer Network through the delivery of decentralized metrics and SLA foundations. This work provides the core infrastructure required to support the Livepeer Foundation’s and Livepeer Inc’s stated Network-as-a-Product (NaaP) initiative, informed by recent Livepeer ecosystem deployments and feedback from the Transformation SPE’s research and focus groups.
Livepeer is evolving from a low-latency, decentralized transcoding network into a productized infrastructure layer capable of delivering predictable, auditable, and programmable services. This evolution requires decentralized metrics and SLA signals. Without them, Livepeer cannot offer verifiable performance guarantees, enable transparent service differentiation, or support intelligent, reliability-aware routing.
Furthermore for Livepeer to succeed as a core infrastructure layer for AI video, robust metrics and SLAs are foundational. Prospective users must be able to evaluate clear performance expectations and costs for common workloads and compare them directly against alternative networks. At the same time, the Livepeer network itself must observe real performance data across popular job types to support effective node selection, job negotiation, and reliability enforcement.
This proposal addresses these requirements by delivering the minimum viable decentralized metrics and SLA primitives necessary to unlock the early phases of the NaaP initiative and support Livepeer’s transition toward production-grade infrastructure.
Cloud SPE has already delivered multiple high-impact public goods to the ecosystem, including the free Cloud SPE Gateway, AI job tester, serverless API infrastructure, orchestrator support tooling, and public transparency dashboards. Building on this proven foundation, the proposed work enables real-time performance visibility and objective SLA measurement across transcoding, AI batch processing, and real-time AI video inference.
This proposal delivers the missing metrics foundation required to move Livepeer from “network” to “networked product,” aligning protocol capabilities with NaaP requirements while preserving decentralization, transparency, and open access. Cloud SPE has the delivery experience and operational context required to execute this work as durable public goods for the Livepeer ecosystem.
Prior Treasury-Funded Work, Operator Experience, & Public Goods
Cloud SPE has completed multiple Livepeer Treasury–funded initiatives delivering protocol-adjacent infrastructure, including public gateways, AI job testing systems, and metrics and transparency tooling that operate in production and interface directly with Livepeer Gateways, Orchestrators, and Workers.
Cloud SPE also operates Livepeer infrastructure as a Gateway, Orchestrator, and Worker operator, including SpeedyBird and Xodeapp. This direct operational experience informs the design of this proposal, ensuring that metrics and SLA primitives reflect real-world performance variability, deployment constraints, and operational trade-offs.
All infrastructure, APIs, schemas, dashboards, and reference implementations delivered through prior and proposed work are operated as public goods and remain openly accessible to the Livepeer ecosystem. Many of these were direct, freely available contributions outside of Treasury proposals with open source code and utilized heavily by many Livepeer participants. These public goods have materially improved both accessibility and adoption across the Livepeer ecosystem. The Cloud SPE will continue to maintain a free public gateway, AI job testing infrastructure, and public metrics dashboards as part of this commitment.
Motivation
Livepeer Inc and the Livepeer Foundation are preparing the future of the network with the NaaP initiative, where the network becomes a product that can be consumed programmatically with:
- Predictable performance
- Transparent metrics
- SLA-backed quality guarantees
- Ability to monitor and deploy workloads
Cloud SPE’s proposed work is instrumental to enabling NaaP. Specifically, this proposal delivers:
- Decentralized events required for SLA and performance calculations
- Canonical SLA scoring primitives for objective evaluation
- Metrics calculation and publishing required for auditability and transparency
When combined, these features make network performance data directly observable and consumable by any participant without intermediaries. This data stream also provides a durable foundation for additional network analytics, including performance diagnosis, capacity planning, and future protocol capabilities built on shared, decentralized metrics.
Problem Statement
In the current Livepeer ecosystem, determining where to send transcoding or AI jobs requires an understanding of node operator capabilities and performance characteristics. The network does not currently provide sufficient real-time, durable data to support this evaluation. Developers are forced to rely on incomplete queries, time-consuming sampling, or centralized measurement, resulting in stale or misleading insights.
This limits the network’s ability to present itself as a predictable and reliable platform for developers and integrators. Without decentralized metrics and SLA signals:
- Performance claims remain unverifiable
- Service differentiation is opaque
- Intelligent routing decisions lack objective grounding
- The network remains best-effort rather than productized
This proposal resolves these gaps by delivering a standardized, decentralized metrics pipeline and SLA foundations that operate across transcoding and AI workloads while surviving node restarts and heterogeneous deployments. These data points in turn can be leveraged to demonstrate the Livepeer Network as a go-to platform with clear service levels and related pricing. In addition, the data will enable Livepeer to objectively evolve towards providing cost-effective scaling and industry-leading latency for real-time AI workloads.
Proposed Work
Below is a focused roadmap aligned with near-term NaaP milestones and targeted for delivery in the first months of 2026, with a metrics catalog under development that enumerates the specific signals addressed within this timeframe.
While no benchmarking or performance-testing system can fully capture a network with rapidly evolving models, workflows, job types, and geographies, this public-goods effort is designed to provide a neutral, transparent, and publicly auditable “universal gateway” view. The goal is to offer a broadly representative baseline for third-party users, rather than relying on the perspective of any single company or narrowly defined production workload.
Milestone 1: Decentralized Metrics Collection & Aggregation
Key Deliverables:
- Evaluate reliability, scalability, and operational suitability of Streamr for decentralized metrics publishing
- Initial standardized event taxonomy and data schema published for community review
- Initial decentralized metrics ingestion and aggregation pipeline
- Correlation of gateway, orchestrator, worker, transcoding, and AI inference metrics
- Validation of durability, partitioning, and access control strategies
- Technical feasibility of Runner <> Orch data sharing
Success Metrics:
- Verified durability across node restarts and heterogeneous deployments
- Community-reviewed event schema
- Demonstrated correlation between gateway, orchestrator, and worker events
This first milestone delivers a validated technical foundation demonstrating that decentralized metrics and data processing can operate reliably across diverse network actors. This milestone emphasizes feasibility and architectural readiness, rather than full production completeness.
Milestone 2: SLA Computation & Observability
Key Deliverables:
- Community-reviewed SLA scoring architecture and data model
- Prototype SLA score computation using historical and near-real-time performance data.
- Public SLA metrics API and documentation
- Basic public dashboards for SLA and performance visibility
Success Metrics:
- Deterministic SLA scores reproducible from published data
- SLA metrics successfully published via an API for evaluation purposes
This milestone delivers objective SLA signals for visibility and evaluation, without enforcing routing or selection changes, and prioritizes correctness and usability over completeness.
Future Possibilities & Follow-On Work
The following capabilities are intentionally deferred to future phases once decentralized metrics and SLA foundations have been validated:
- SLA-informed selection logic integrated into go-livepeer
- Open Pool enhancements based on SLA signals
- Orchestrator and worker onboarding workflow improvements
- Enforcement mechanisms or policy-level SLA guarantees
- Advanced metrics exploration (e.g., CUDA Utilization Efficiency [CUE])
- Expanded dashboards and developer tooling
These items represent a natural and well-defined progression path for Livepeer in its journey towards being a reliable and scalable platform.
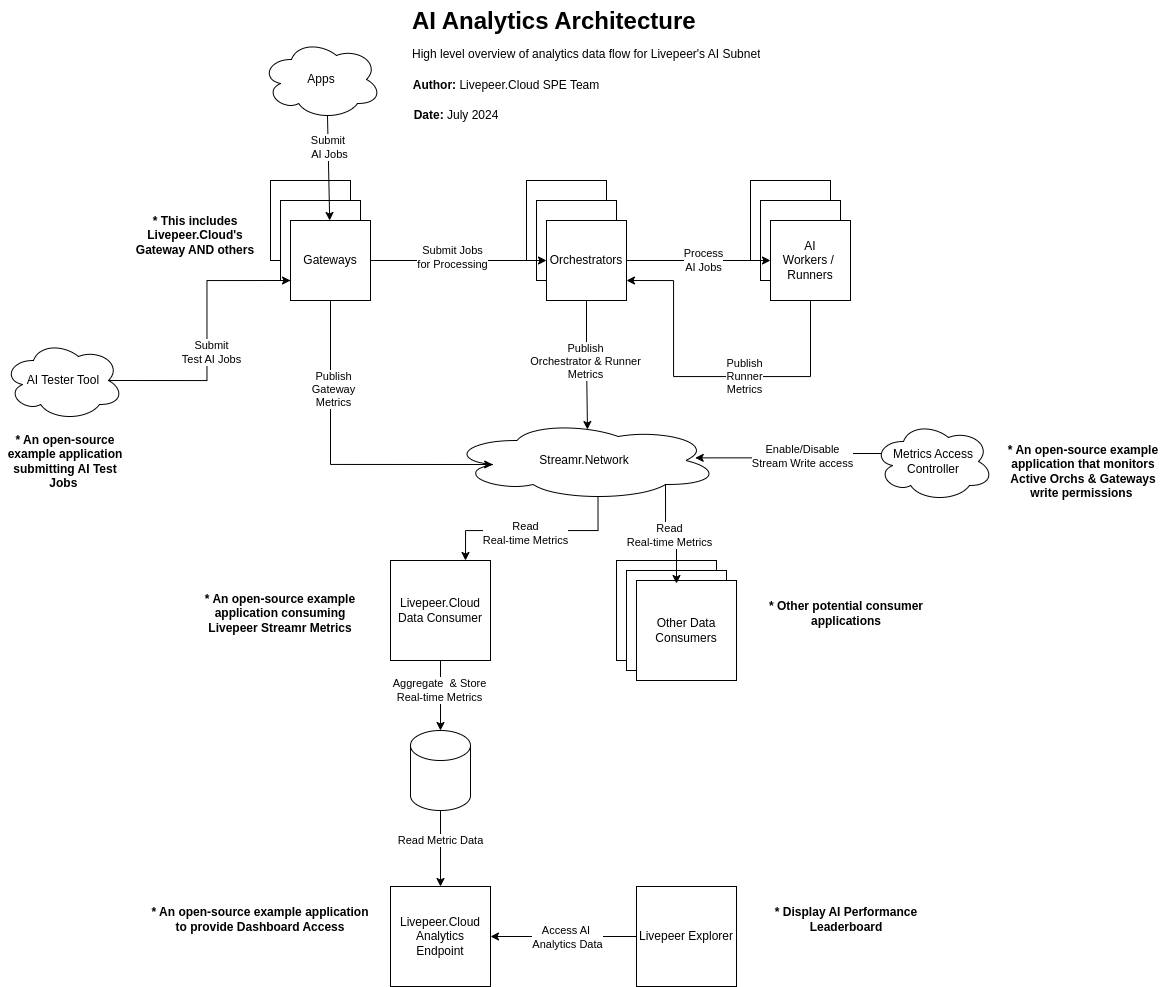
Technical Architecture Overview
The AI Analytics architecture is a modular, real-time metrics pipeline designed to observe, stream, aggregate, and present performance data across Livepeer. It cleanly separates job execution from analytics, enabling scalable monitoring without impacting network operations.
The approach embraces decentralization and data democratization by publishing data directly from nodes for public consumption. This enables data to be consumed without having to deal with service discovery of all Orchestrators, which currently is limited by manual processes or network topology. As nodes operate through their lifecycle, including when processing a job, they will emit events detailing the activity that are published to a configurable set of channels. For the proposed solution, we will focus on leveraging Streamr, a decentralized data network, as the channel. A data consumer will then pull this data down from a Streamr stream, conduct various transformations, and publish them to a data warehouse. This consumer can be hosted by anyone (enabling other Gateway providers to host privately and adapted as needed), and the Cloud SPE will host an instance for public use. During the day-to-day operations of Livepeer, different node types will be producing data to ensure a holistic, trustworthy set of data. This means that Gateways, Orchestrators, and Worker Nodes will contribute data. This data will then be able to be correlated for deep insights and cross-validation to limit bad actors and accurately measure jobs as they pass through the network. Lastly, an API will be built to enable Gateways to leverage these data points and for a public dashboard that enables visibility into the network.
Core Components:
- Job Tester/Gateway - Responsible for validating network based on public test scenarios
- Metrics Publisher - integrated with go-livepeer; pushes data between and from nodes to a decentralized event stream
- Metrics Access Controller - controller for publishing data to ensure only active Orchestrators can publish data
- ETL Pipeline - Data transformation engine to read event logs and produce metrics (e.g. SLA score)
- Data Warehouse for metric storage
- API Layer for scoring, dashboards, workflows
- Analytics Dashboard - minimal, publicly accessible with data from ETL engine
The architectural components and data flow can be visualized as follows.
A detailed breakdown of this diagram can be found here.
Deliverables Summary
We will perform extensive testing to ensure accuracy and reliability. This will include automation as well as manual testing of metrics generation, data stream publishing, data stream consumption, metrics processing, APIs, and dashboards. Based on the results of our testing as well as insights gained from the current Livepeer Cloud usage, we will optimize where appropriate.
Each milestone will conclude with:
- A public demo
- Code proposed for merge or published to a public repository
- Documentation and community review
After completion of the proposal, all code will be put up for review and inclusion into several key GitHub repositories including go-livepeer and others as needed. All of this code will be available to the public to deploy for their own use cases.
Livepeer.Cloud (SPE) Infrastructure will be updated to run all the latest analytics solutions and can be thought of as a “reference implementation” for future/current Gateway Operators. Cloud SPE will operate this infrastructure as a reference implementation and address issues identified through ongoing use. Operational findings may result in minor corrective updates necessary to ensure correctness and reliability.
Core Deliverables
| Category | Deliverables |
|---|---|
| Metrics | Decentralized publishing, taxonomy, durability, storage |
| SLA | Computation, API, scoring models, documentation |
| Dashboard | Metrics explorer, SLA summary |
| Community Tools | APIs, repo docs, SDK examples, Docker templates |
| Public Goods | AI testers, APIs, Streamr datasets |
Delivery Approach & Iteration
This proposal reflects an ambitious but focused scope intended to deliver meaningful foundations. Cloud SPE will prioritize delivery of the core decentralized metrics and SLA primitives described above, and will iterate on implementation details as development progresses to ensure correctness, usability, and reliability.
As with prior work, scope and technical decisions will be informed by real-world testing, operational feedback, and ongoing collaboration with the community. Where trade-offs are required, preference will be given to delivering durable, extensible primitives rather than incomplete or brittle features. This approach ensures the work remains aligned with available resources while producing outputs that can be confidently extended in future phases.
Governance
The SPE team will distribute the funds among themselves after payment. The community’s input before and during the SPE will be collected via:
- A Livepeer forum post seeking feedback on the proposal prior to submission.
- Attendance at the Weekly Water Cooler Chat to discuss the proposal, collect feedback, and reshape (if necessary) the proposal prior to funding.
- After approval, the team will continue to attend the Water Cooler to present progress and a monthly update in the Livepeer forum.
Funding
The requested funding reflects a focused scope across two milestones that establish the benchmarks Livepeer requires to credibly position its cost and performance against other providers. This includes:
- Requirements, Development, Testing, and Documentation
- Community, Livepeer Inc, Livepeer Foundation and AI SPE Collaboration and Engagement
- Enhancements include the Livepeer metrics framework, Streamr integration, AI Job Tester improvements, analytics consumers, and a public ‘reference implementation’ API.
- SPE Hardware and DevOps (Development and Production)
| Milestone | Scope | Amount |
|---|---|---|
| Milestone 1 | Decentralized metrics foundation | $100,000 |
| Milestone 2 | SLA computation & observability | $80,000 |
| DevOps & Infrastructure | Hosting, hardware, and job testing costs | $20,000 |
| Total | $200,000 |
Timeline
Delivery is anticipated to take approximately six months (and already underway as of November 2025). This is dependent on the team’s development velocity and subject to change. Preliminary design and validation work has begun to reduce delivery risk.
- November 2025 - Works begins on Milestone 1
- February 2026 – Milestone 1: Decentralized Metrics Foundation
- April 2026 – Milestone 2: SLA Computation & Observability
Conclusion
This proposal aims to implement a real-time analytics foundation for Livepeer node operators, leveraging the Streamr Network to democratize performance monitoring and decision-making. By publishing real-time metrics, we will provide valuable insights into node performance, reliability, and capabilities, ultimately improving the overall efficiency and robustness of the Livepeer protocol through the enablement of the Network as a Product initiative (NaaP) and programmable SLAs.
Cloud SPE has delivered significant public goods, transparency tooling, and gateway infrastructure that have meaningfully improved the Livepeer ecosystem. With the direct engagement of Livepeer Inc and the Livepeer Foundation as our design partners, this next project will unlock a critical requirement for NaaP: decentralized metrics and SLA scoring
We respectfully request Treasury funding to execute this roadmap and provide the foundational building blocks for Livepeer’s transition into a robust, productized decentralized video and AI infrastructure network.
Cloud SPE has the delivery experience and operational context required to execute this work.
